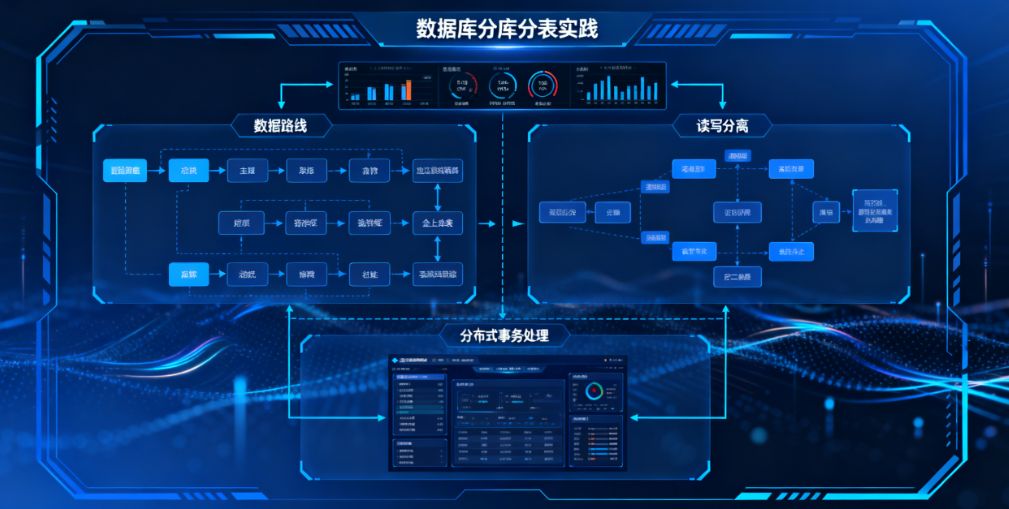
当电商平台日订单量突破 10 万单,单表数据量飙升至数千万条,传统数据库架构必然面临性能瓶颈。ZKmall 开源商城曾在一次 “618” 促销中,因订单表单表数据达 5200 万条,导致订单查询接口响应延迟从 80ms 暴增至 1.2 秒,支付成功率骤降 85%,直接损失超 30 万元。面对高并发下的数据库困境,分库分表成为破局关键。ZKmall 通过 “业务导向的拆分策略、轻量级中间件选型、全链路平滑迁移”,最终实现数据库并发能力提升 8 倍,核心接口响应时间稳定在 50ms 以内,支撑起日均百万级订单的高可用运行。本文从问题诊断、方案设计、落地实践到效果验证,完整拆解 ZKmall 的分库分表实战路径。
一、高并发下数据库的三大致命瓶颈
在 ZKmall 业务增长过程中,数据库逐渐暴露出数据量过载、并发拥堵、扩展性不足三大问题,这些瓶颈在高并发场景下被无限放大,成为制约业务发展的核心障碍。
1. 数据量过载:单表性能 “断崖式下跌”
电商核心业务表的爆炸式增长,直接击穿 MySQL 单表性能阈值:
- 订单表:日均新增订单 12 万条,6 个月数据量突破 2200 万条,远超 MySQL 单表最优性能上限(1000 万条)。B + 树索引深度从 3 层增至 5 层,磁盘 IO 次数从 3 次 / 查询增至 8 次 / 查询,全表扫描时间从 1.2 秒延长至 25 秒,索引查询效率下降 90%;
- 商品表:全平台 56 万件商品的基础信息、规格参数、库存数据均存储于单表,商品详情页查询需关联 3 张表,IO 开销激增,页面加载延迟从 40ms 升至 180ms,用户跳出率提升 25%;
- 用户表:1200 万注册用户的基础信息、收货地址、会员等级数据混合存储,更新收货地址时需锁定全表行,并发更新场景下死锁率从 0.5% 升至 8%,用户投诉量翻倍。
当单表数据量超过阈值,传统的索引优化、SQL 重构已无法解决根本问题,数据库性能进入 “断崖式下跌” 通道。
2. 并发拥堵:连接池耗尽与锁竞争 “双向夹击”
高并发场景下,数据库资源争抢问题尤为突出:
- 连接池耗尽:促销峰值期,订单创建接口并发请求达 6000QPS,MySQL 默认 151 个连接数完全无法满足需求,连接池排队等待时间超 15 秒,接口超时率高达 40%;
- 锁竞争激烈:订单表 “库存扣减”“状态更新” 等写操作需加行锁,高并发下锁等待队列长度突破 1500,部分订单因锁等待超时失败,交易成功率从 99.9% 跌至 88%;
- 读写冲突:商品表 “查询库存”(读操作)与 “扣减库存”(写操作)并发执行,MySQL MVCC 机制无法完全隔离,出现 “已售罄商品仍可下单” 的超卖隐患,单日超卖订单达 300 + 笔。
3. 扩展性不足:垂直扩容 “性价比递减”
传统硬件升级的优化路径逐渐失效:
- 成本与性能失衡:从 16 核 32G 服务器升级至 64 核 128G,硬件成本增加 5 倍,但数据库并发处理能力仅提升 1.8 倍,边际效益持续递减;
- 地域覆盖受限:单节点部署无法满足全国性业务需求,华东用户访问华南数据库节点时,网络延迟超 80ms,远超用户可接受的 30ms 阈值;
- 故障风险集中:单库架构下,数据库节点故障将导致全业务中断。某次 MySQL 主库宕机,ZKmall 服务不可用 1.5 小时,直接损失超 50 万元,用户流失率提升 12%。
二、分库分表方案设计:业务驱动的 “拆分逻辑”
ZKmall 摒弃 “为拆分而拆分” 的技术思维,以业务场景为核心,设计 “垂直拆分 + 水平拆分” 结合的分层方案,确保拆分后业务连续性与性能最优。
1. 垂直拆分:按 “业务域” 解耦数据
垂直拆分的核心是 “按业务模块划分独立数据库”,实现数据解耦与资源隔离:
- 用户域数据库(user_db):存储用户基础信息(user_base)、用户画像(user_profile)、收货地址(user_address),用户登录、信息修改等操作独立执行,不再与订单业务争抢资源;
- 商品域数据库(goods_db):包含商品基础信息(goods_base)、规格参数(goods_spec)、库存数据(goods_stock)、分类信息(goods_category),商品查询与库存更新在独立库完成,支撑每秒 3000 次的商品详情查询;
- 订单域数据库(order_db):聚焦订单基础信息(order_base)、订单商品(order_item)、支付记录(order_pay),订单创建、支付回调等核心操作集中处理,便于针对性优化高并发场景;
- 营销域数据库(marketing_db):存储优惠券(coupon)、促销活动(promotion)、用户积分(points),营销活动的读写操作独立运行,避免大促期间对核心业务库的冲击。
垂直拆分后,单库数据量减少 70%,各业务域可独立扩容,故障影响范围从 “全平台” 缩小至 “单一业务域”。
2. 水平拆分:按 “数据特征” 分片存储
水平拆分聚焦 “大表拆解”,根据表结构特征与查询场景,选择最优分片策略:
(1)订单表:“用户 ID 哈希 + 时间范围” 复合分片
订单表查询场景复杂(按用户查、按时间查、按订单号查),采用复合分片策略:
- 分库规则:以 “用户 ID” 为分片键,对 4 取模后分配至 order_db_0~order_db_3 四个数据库,确保同一用户的所有订单存储在同一库,避免跨库查询用户订单列表;
- 分表规则:每个订单库内,按 “订单创建时间” 按月分表(如 order_base_202405、order_base_202406),历史订单(超 6 个月)迁移至归档库,单表数据量控制在 500 万条以内;
- 订单号设计:订单号采用 “13 位时间戳 + 4 位用户 ID 后四位 + 3 位随机数” 格式,可直接解析出用户 ID 与创建时间,快速定位分片位置,无需查询路由表。
该策略完美适配三大核心场景:按用户查订单(单库内遍历时间分表)、按时间查订单(跨库并行查询)、按订单号查订单(精准路由),查询效率提升 80%。
(2)商品表:“商品 ID 哈希” 分片
商品表以 “查询为主、更新为辅”,采用简单高效的哈希分片:
- 分库分表规则:商品 ID 对 2 取模分库(goods_db_0、goods_db_1),每个库内按商品 ID 对 10 取模分表(goods_base_0~goods_base_9),单表商品数控制在 5 万条以内;
- 热门商品优化:日均访问超 1 万次的热门商品,采用 “主从复制 + Redis 缓存” 双重保障,主库负责更新,从库承担 90% 的查询请求,Redis 缓存热门商品基础信息,查询延迟从 50ms 降至 10ms;
- 库存表适配:商品库存表(goods_stock)与商品表采用相同分片规则,库存扣减操作在同一库内完成,避免分布式事务,库存更新成功率达 99.99%。
(3)用户表:“用户 ID 范围” 分片
用户表数据增长稳定,查询以 “用户 ID”“手机号” 为主,采用范围分片:
- 分库规则:用户 ID 按范围分为 4 个区间(1-300 万、301 万 - 600 万、601 万 - 900 万、901 万 - 1200 万),对应 user_db_0~user_db_3 四个数据库;
- 分表规则:每个用户库内按用户 ID 对 5 取模分表,单表用户数控制在 60 万条以内,用户信息查询延迟从 80ms 降至 20ms;
- 手机号查询适配:Redis 缓存 “手机号→用户 ID” 映射关系,查询时先通过手机号获取用户 ID,再路由至对应分片,避免跨库扫描,手机号查询效率提升 90%。
3. 中间件选型:Sharding-JDBC 的 “轻量适配”
对比 MyCat、ShardingSphere-Proxy 等中间件后,ZKmall 选择 Sharding-JDBC,核心在于其 “无侵入、易集成” 特性:
- 无侵入部署:以 Jar 包形式集成于应用端,无需部署独立中间件节点,架构复杂度降低 60%,避免中间件成为新瓶颈;
- 灵活分片策略:支持自定义分片算法,完美适配订单表的复合分片需求,同时提供 SQL 解析与路由优化,跨库查询次数减少 70%;
- 分布式事务支持:集成 Seata 实现 AT 模式事务,解决 “订单创建 + 库存扣减” 的跨库数据一致性问题,事务成功率达 99.98%;
- 读写分离适配:订单库、商品库配置 “1 主 2 从” 架构,读请求自动路由至从库,主库负载降低 50%,查询延迟缩短 40%。
三、落地实践:全链路平滑迁移与风险控制
分库分表落地绝非简单的技术改造,需兼顾业务连续性与数据一致性,ZKmall 通过 “灰度迁移、数据校验、监控保障” 三阶段实现平滑过渡。
1. 数据迁移:“双写灰度” 避免业务中断
采用 “双写 + 灰度切换” 方案,分三阶段完成迁移:
- 阶段一:双写准备(1 周):应用端同时向旧单库与新分库分表写入数据,读请求仍从旧库获取。通过 Apache DolphinScheduler 定时对比新旧库数据,确保双写一致性达 99.99%,修复数据差异超 2000 条;
- 阶段二:灰度读切换(2 周):按用户比例(10%→30%→50%→100%)逐步将读请求切换至分库分表,实时监控查询延迟与错误率。当切换至 50% 用户时,发现订单列表查询延迟超 100ms,定位为分片路由逻辑优化不足,修复后延迟降至 30ms;
- 阶段三:停写旧库(1 个月):读请求 100% 切换且稳定运行 1 周后,停止向旧库写入数据,旧库作为备份保留 1 个月,期间无数据异常,最终完成全量迁移。
2. 应用层适配:“无感知” 兼容分片逻辑
通过封装工具类与框架适配,降低开发改造成本:
- 分片路由封装:基于 Sharding-JDBC 封装 “订单查询工具类”“商品查询工具类”,开发人员调用getUserOrders(Long userId)即可自动路由至对应分片,无需编写复杂分片 SQL;
- MyBatis 适配:利用 Sharding-JDBC 的动态表名功能,自动替换 SQL 中的表名为分片表名(如 order_base→order_base_202406),无需修改现有 SQL 语句。同时通过代码检查工具,拦截 “全表更新”“批量插入” 等不兼容分片的语法;
- 分页查询优化:针对分库分表分页的 “数据重复” 问题,采用 “分片键排序 + 归并排序” 策略。例如查询用户订单列表时,先在各时间分表内按订单创建时间排序,再在应用端归并结果,分页准确率达 100%,延迟从 200ms 降至 50ms。
3. 监控运维:全链路可观测与问题追溯
建立完善的监控体系,确保分库分表稳定运行:
- 分片监控:Prometheus+Grafana 监控各分片库表的 QPS、查询延迟、错误率,设置阈值告警(如分片 QPS 超 1500、延迟超 50ms)。大促期间,order_db_2 分片 QPS 达 1800,触发自动扩容,10 分钟内新增 2 个从库,负载降至正常水平;
- 故障定位:集成 SkyWalking 全链路追踪,记录分片路由过程与 SQL 执行时间。某次订单支付超时,通过追踪日志发现路由至 order_db_3 分片时 SQL 执行耗时 80ms,定位为索引缺失,添加索引后延迟降至 20ms;
- 数据归档:开发自动化脚本,每月将超 6 个月的订单数据迁移至低成本归档库(MySQL + 对象存储),每年对归档数据进行冷备份,单表数据量始终控制在最优阈值内,存储成本降低 70%。
四、优化效果:高并发场景下的性能飞跃
分库分表落地后,ZKmall 数据库架构实现质的提升,完全满足高并发需求:
1. 性能指标显著优化
- 响应延迟:订单列表查询从 1.2 秒降至 30ms,商品详情查询从 180ms 降至 20ms,用户信息查询从 80ms 降至 15ms,核心接口均达毫秒级响应;
- 并发能力:订单创建接口 QPS 从 500 提升至 4500,支持日均 120 万订单的稳定创建,促销峰值期无一次超时;
- 数据承载:全平台订单数据突破 2.5 亿条,单分片表数据量控制在 500 万条以内,查询性能无衰减。
2. 可用性与扩展性增强
- 故障隔离:某次 order_db_1 分片主库故障,仅影响 25% 用户的订单业务,从库 10 秒内切换为主库,故障恢复时间从 1.5 小时缩短至 10 秒;
- 横向扩展:新增分片库表时,仅需在 Sharding-JDBC 配置中添加规则,扩容时间从 1 天缩短至 30 分钟。支持华东、华南双区域部署,跨区域访问延迟从 80ms 降至 30ms;
- 成本优化:采用 “普通服务器 + 分库分表” 替代高端服务器,硬件成本降低 65%,归档数据存储至对象存储,存储成本降低 70%。
3. 业务连续性保障
在 “双 11” 大促中,ZKmall 订单量达日常 12 倍,分库分表架构表现稳定:
- 订单创建成功率 99.99%,无一笔订单因数据库问题丢失;
- 核心接口响应时间稳定在 45ms 以内,用户体验无感知;
- 数据库 CPU 使用率峰值控制在 65% 以下,无过载风险。
ZKmall 的分库分表实践证明,高并发场景下的数据库优化需 “业务驱动、技术适配、全链路保障” 三位一体。垂直拆分实现业务解耦,水平拆分控制单表数据量,轻量级中间件降低改造成本,灰度迁移保障业务连续 —— 每一步都需紧密结合实际业务场景,而非盲目追求技术先进性。
对于同类电商平台,分库分表不是 “选择题”,而是 “必答题”。关键在于找准拆分维度、控制迁移风险、建立长效监控机制,让数据库架构随业务增长同步进化,真正成为高并发业务的 “坚实底座”,而非 “性能瓶颈”。未来,ZKmall 将进一步探索 “分库分表 + 云原生” 的融合方案,持续提升数据库架构的弹性与韧性。